
LinkedIn's Cookie Consent Notice
2024-07-05
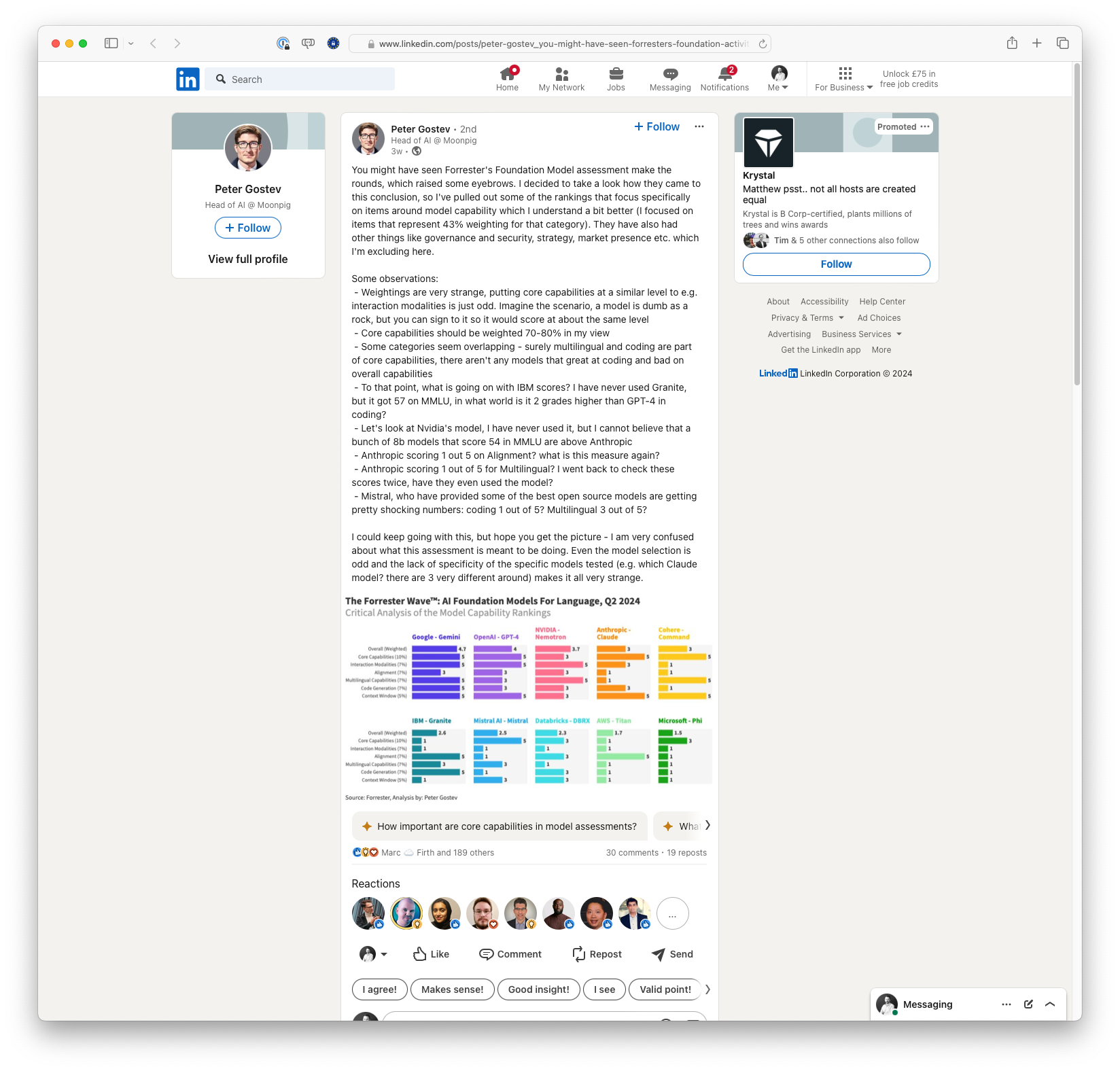

Peter Gostev, Head of AI at Moonpig, critiques Forrester's Foundation Model assessment for its confusing weightings and scores, especially questioning the logic behind the rankings for core capabilities and specific models, such as IBM's and Anthropics'. He highlights the overlap in categories and the odd results for well-regarded open-source models like Mistral.
Was this useful?