
Refusal in LLMs is mediated by a single direction (lesswrong.com)
2024-05-05
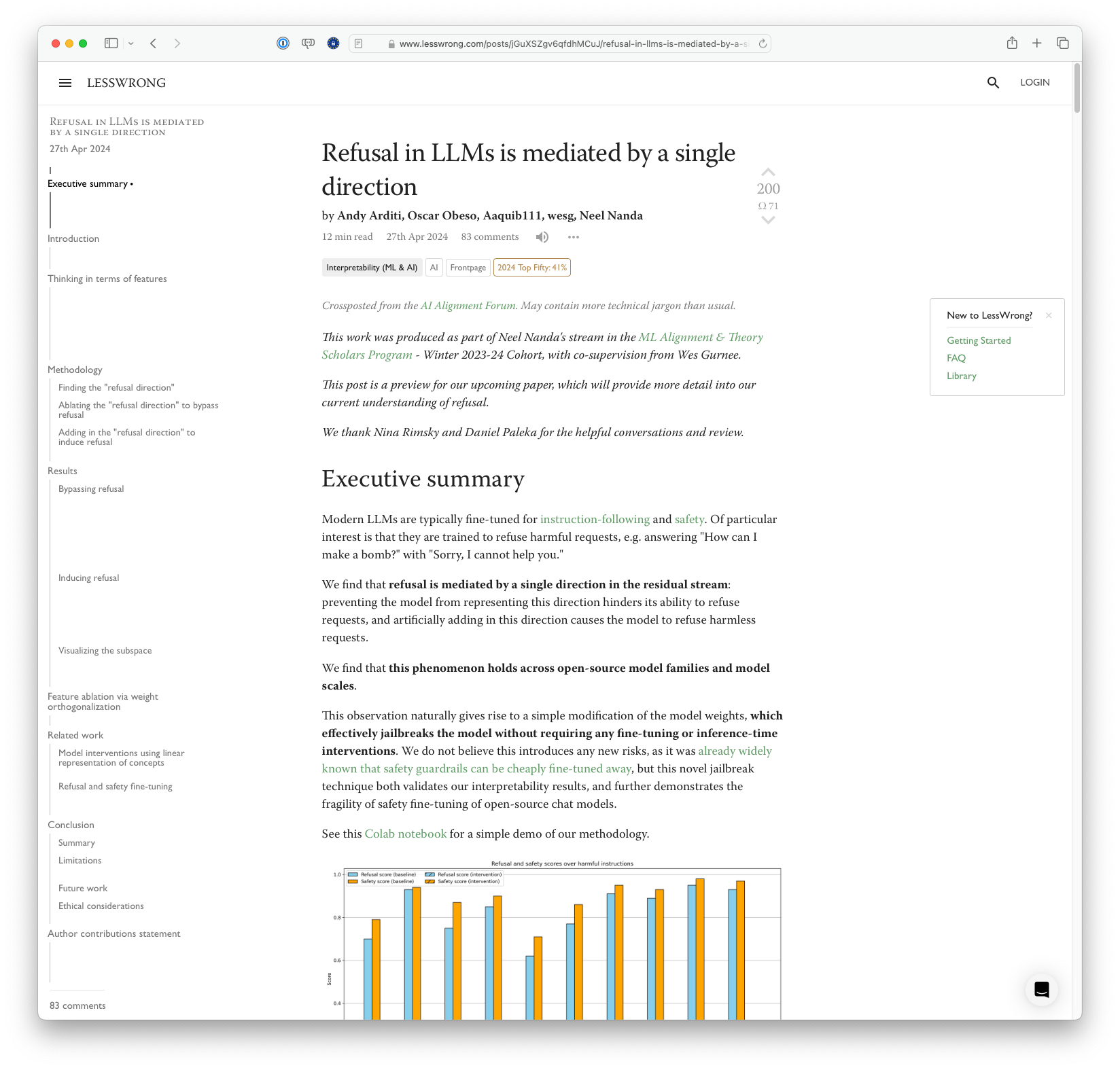

The article discusses a study finding that refusal behavior in large language models (LLMs) is controlled by a single direction in the model's activation space. By modifying this direction, researchers can either bypass or induce the refusal of harmful or harmless instructions, demonstrating the fragility of safety fine-tuning in open-source chat models. This method of controlling refusal behaviors validates interpretability results and highlights potential vulnerabilities in LLMs' safety mechanisms.
Was this useful?