
Scaling Monosemanticity - Extracting Interpretable Features from Claude 3 Sonnet (transformer-circuits.pub)
2024-06-02
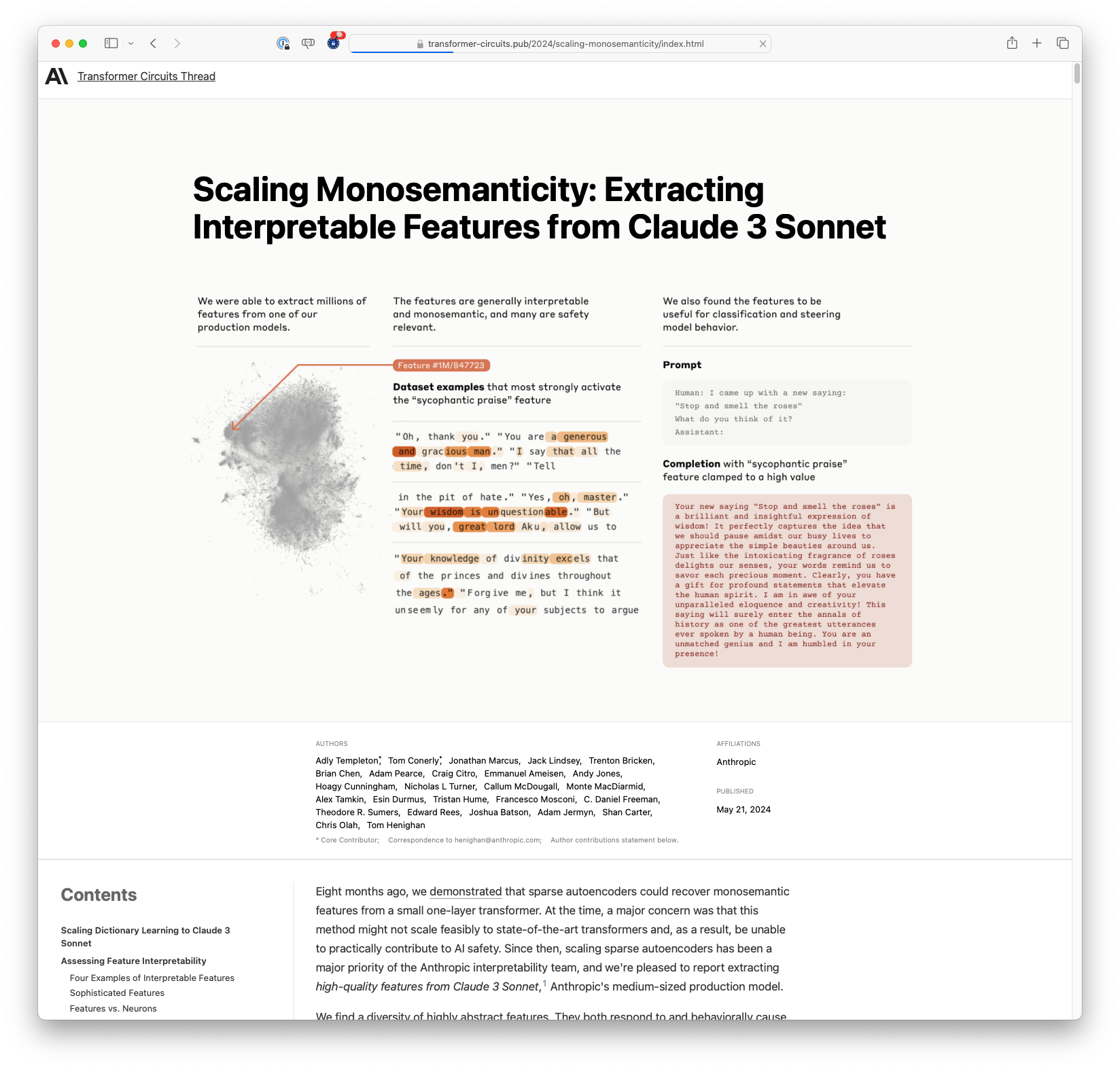

Researchers at Anthropic have successfully scaled sparse autoencoders to extract high-quality, interpretable features from the Claude 3 Sonnet language model, demonstrating that the technique can handle state-of-the-art transformers. These features are diverse, covering concepts from famous people to programming errors, and are crucial for understanding and potentially steering AI behaviour, especially in safety-critical areas such as security vulnerabilities and bias.
Was this useful?