
Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
2024-06-02
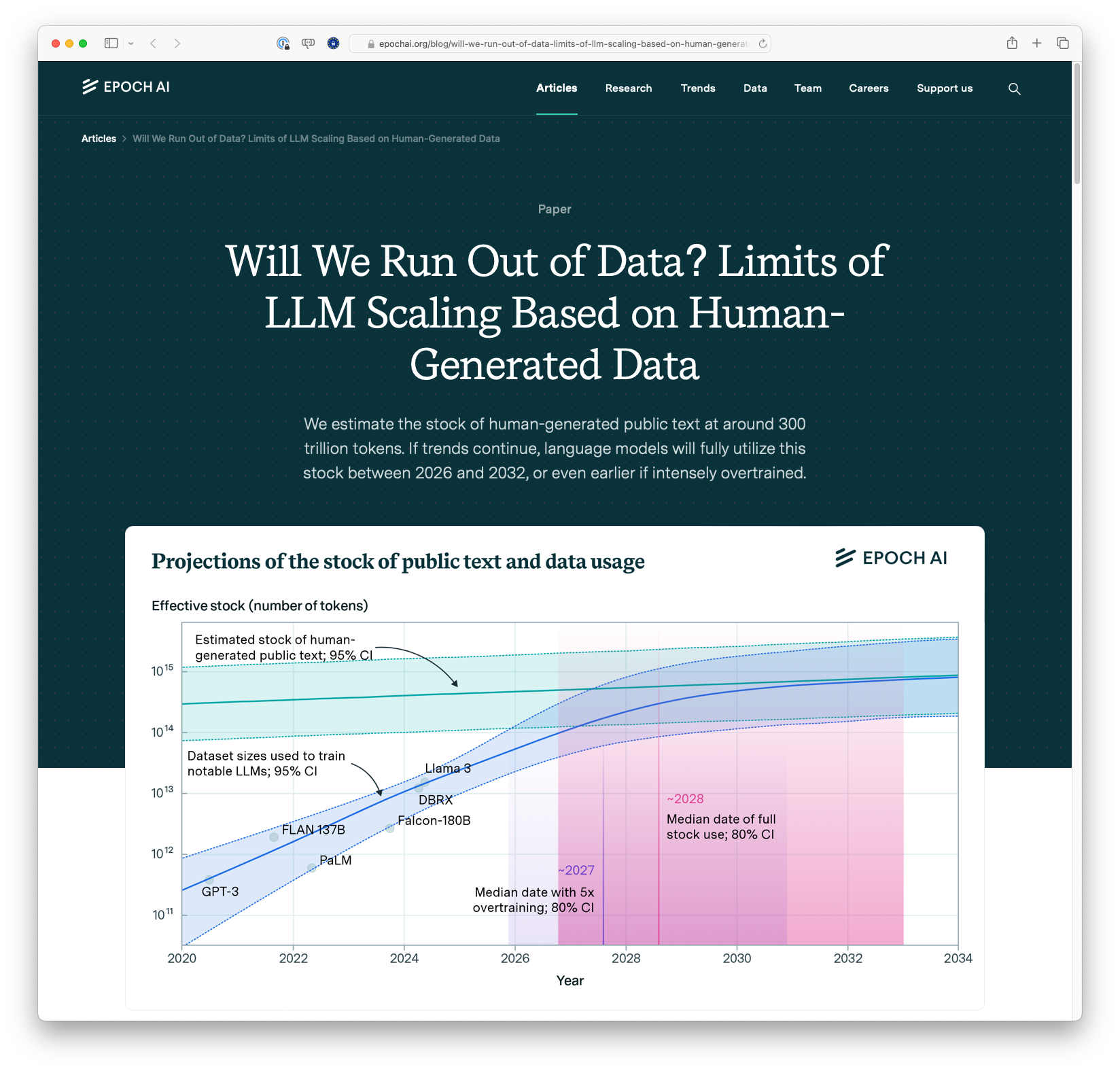

Epoch AI has estimated the total supply of human-generated public text at about 300 trillion tokens. They project that, at the current rate of usage, language models will exhaust this data stock by 2026 to 2032, or even earlier with high-frequency training. Their forecast also explores the impact of different training strategies on data consumption, noting that models trained beyond computed-optimal levels might leverage more data to enhance training efficiency. The discussion includes possible avenues to sustain AI progress, such as developing synthetic data, tapping into other forms of data, and improving data efficiency.
Was this useful?