
Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
2024-07-01
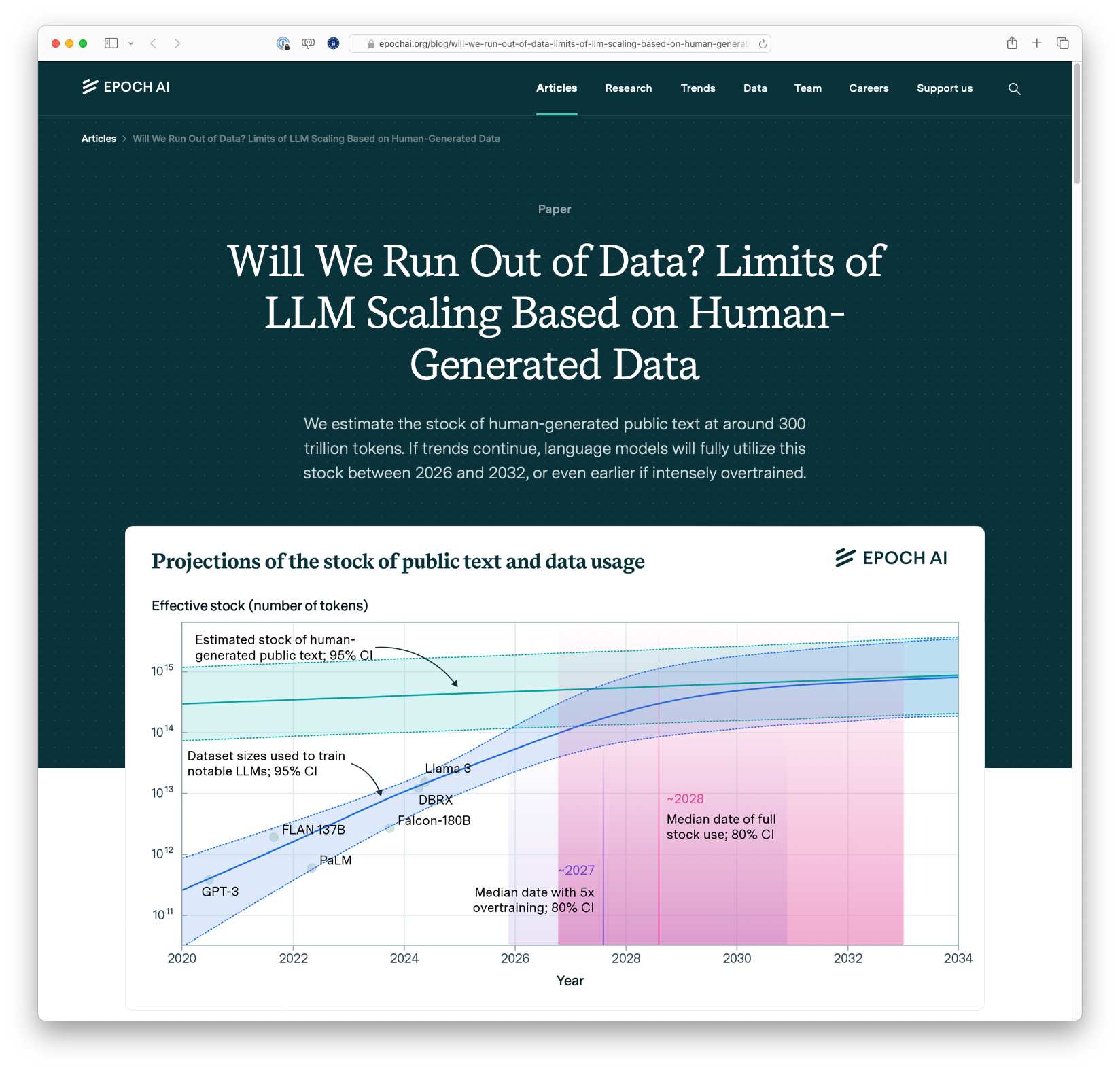

The article discusses the potential limits of data availability for training large language models (LLMs). It estimates the current stock of human-generated public text at around 300 trillion tokens and projects that this data could be fully utilized between 2026 and 2032, depending on various scaling strategies. The piece also highlights recent findings that suggest effective ways of using and extending current data stocks, including overtraining models and utilizing multiple epochs of training data.
Was this useful?