
Apple study exposes deep cracks in LLMs’ “reasoning” capabilities
2024-10-12
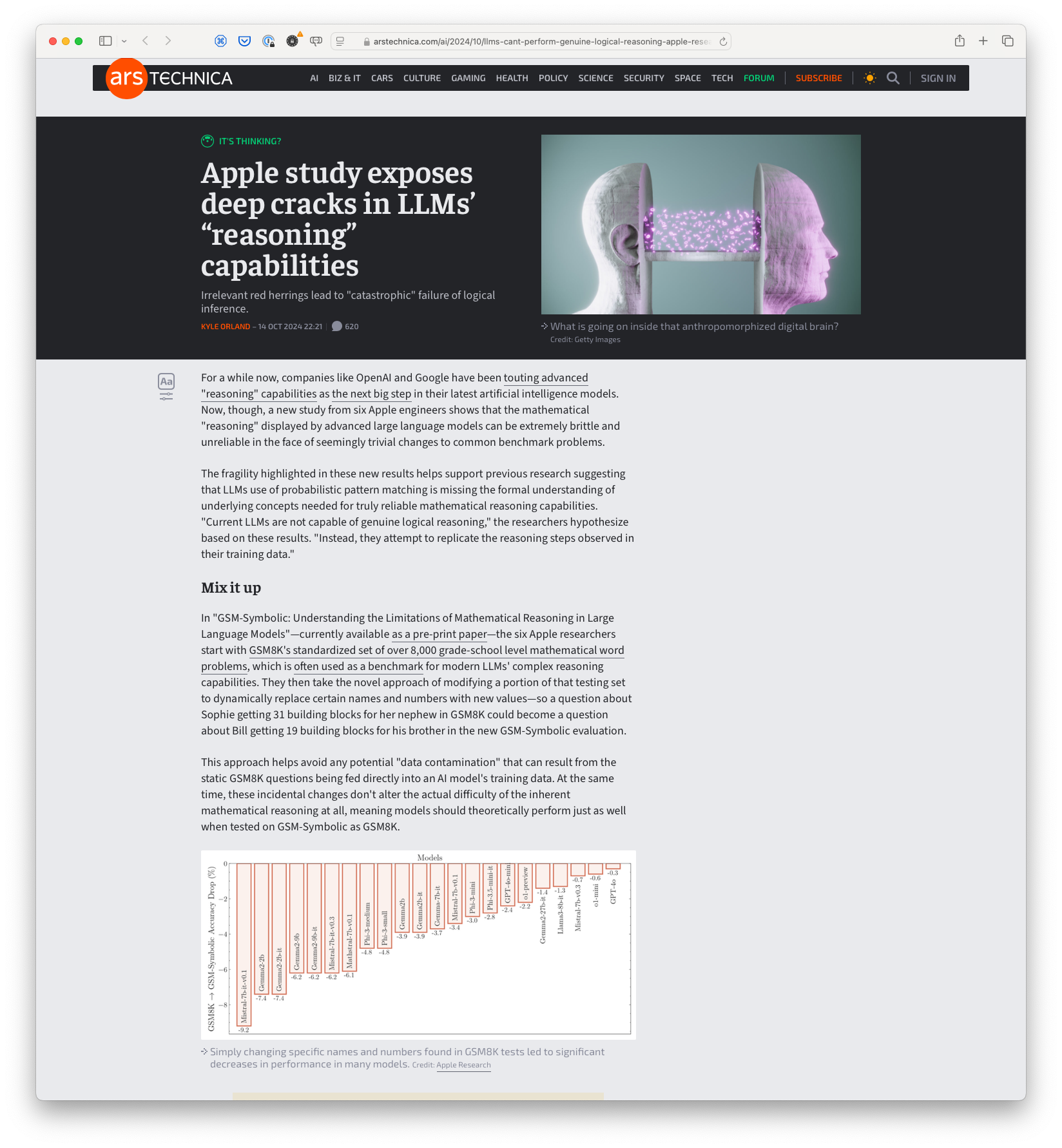

A recent study conducted by Apple researchers reveals significant vulnerabilities in the reasoning capabilities of large language models (LLMs). These models often fail at logical inference tasks, especially when faced with minor changes in problem scenarios, leading to what researchers term "catastrophic" drops in performance. The study highlights that current LLMs are not capable of genuine logical reasoning, but rather, replicate patterns from training data. The findings emphasize the fragility of LLMs in truly grasping underlying mathematical concepts, suggesting that without genuine reasoning abilities, these models remain brittle in unexpected situations.
Was this useful?