
Understanding Reasoning LLMs
2025-02-17
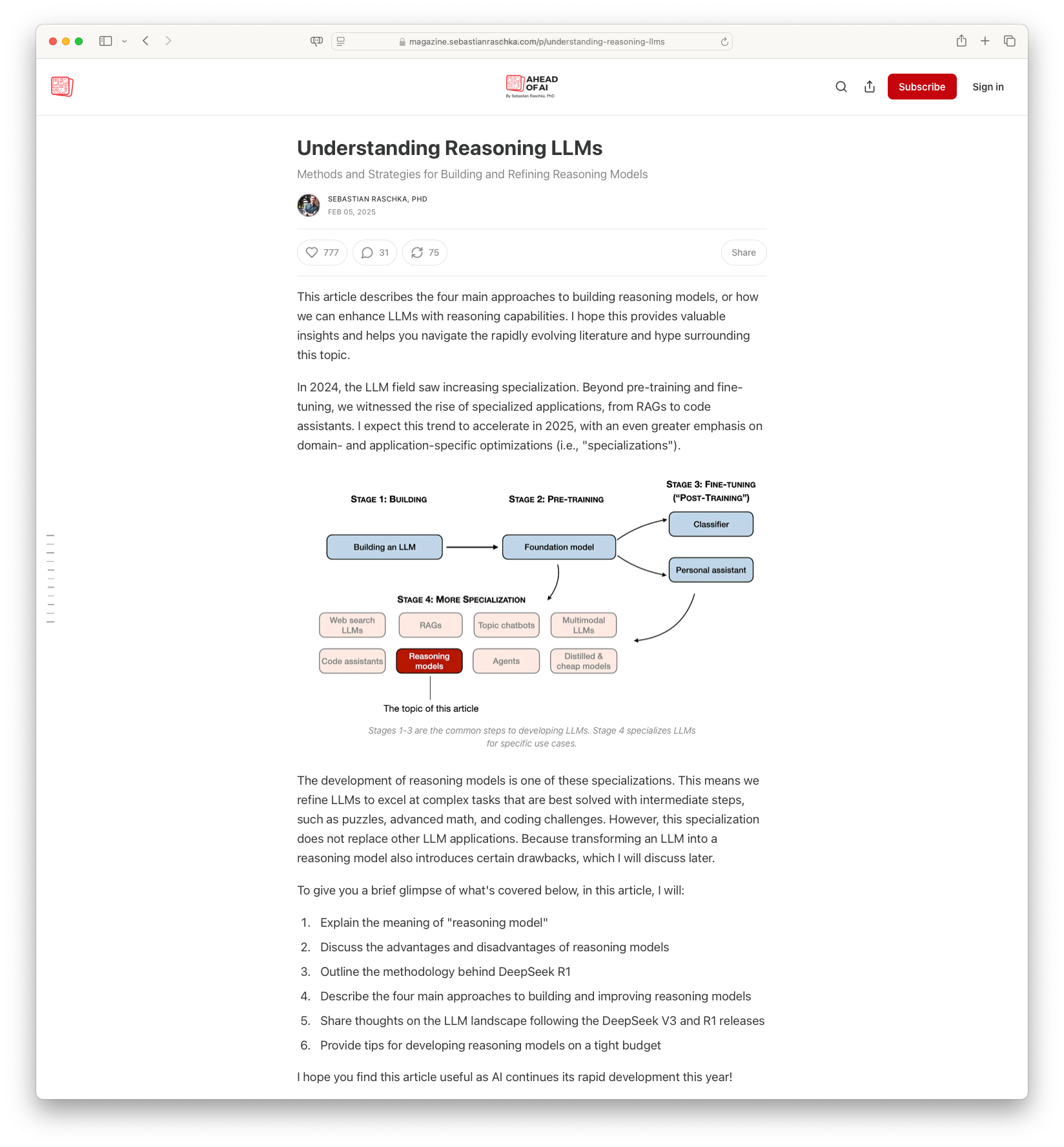

The article by Sebastian Raschka, PhD, delves into the methodologies for enhancing reasoning capabilities within large language models (LLMs). It explains the four primary strategies for developing reasoning LLMs: inference-time scaling, pure reinforcement learning, supervised fine-tuning combined with reinforcement learning, and model distillation. Various cases like DeepSeek R1 are explored, highlighting how reasoning can emerge through reinforcement learning and the importance of supervised fine-tuning for more efficient and capable models.
Was this useful?