
QFM064: Irresponsible Ai Reading List - April 2025
 Source: Photo by Luis Villasmil on Unsplash
Source: Photo by Luis Villasmil on Unsplash
This month's Irresponsible AI Reading List reveals fundamental gaps between AI hype and practical reality. Recent AI Model Progress Feels Mostly Like Bullshit{:target="_blank"} provides a direct assessment of recent AI advancements, arguing that despite marketing claims and test improvements, these models fail to deliver significant practical benefits or economic value in real-world applications. This connects to There is no Vibe Engineering{:target="_blank"}, which challenges the concept of "vibe coding" popularised by Andrej Karpathy, arguing that whilst AI assists with prototyping, it lacks the robustness required for true software engineering that involves designing evolutive systems.
Security vulnerabilities expose systemic weaknesses across multiple fronts. Novel Universal Bypass for All Major LLMs{:target="_blank"} demonstrates a new prompt injection technique that bypasses safety guardrails in major AI models from OpenAI, Google, and Microsoft, highlighting insufficient reliance on Reinforcement Learning from Human Feedback for model alignment. Meanwhile, AI-generated code could be a disaster for the software supply chain{:target="_blank"} reveals how AI generates 'hallucinated' package dependencies that create opportunities for supply-chain attacks through phantom libraries, particularly affecting JavaScript ecosystems.
Surveillance and geopolitical threats demonstrate AI's role in authoritarian applications. The Shocking Far-Right Agenda Behind the Facial Recognition Tech Used by ICE and the FBI{:target="_blank"} exposes how Clearview AI's facial recognition technology, built from scraped online images, enables warrantless surveillance targeting immigrants and political adversaries.
This connects to The one interview question that will protect you from North Korean fake workers{:target="_blank"}, which reveals how North Korean agents use generative AI to create fake LinkedIn profiles for remote employment infiltration.
Content manipulation and attribution challenges highlight AI's impact on information integrity. LLMs Don't Reward Originality, They Flatten It{:target="_blank"} examines how large language models favour consensus over original ideas, creating 'LLM flattening' that dilutes unique insights in favour of widely recognised concepts. Technical evidence of manipulation appears in New ChatGPT Models Seem to Leave Watermarks on Text{:target="_blank"}, which identifies special Unicode character watermarks in ChatGPT output, though OpenAI clarifies these as unintentional quirks from reinforcement learning rather than deliberate watermarks.
Human deception and verification receive attention through practical scenarios. What it's like to interview a software engineer preparing with AI{:target="_blank"} describes candidates using AI for interview preparation, revealing gaps in truthfulness that require deeper situational questioning to assess genuine abilities. Creative countermeasures appear in Benn Jordan's AI poison pill and the weird world of adversarial noise{:target="_blank"}, which demonstrates embedding imperceptible adversarial noise into audio files to prevent unauthorised AI training on music, though current methods demand significant computational resources.
As always, the Quantum Fax Machine Propellor Hat Key will guide your browsing. Enjoy!

Links
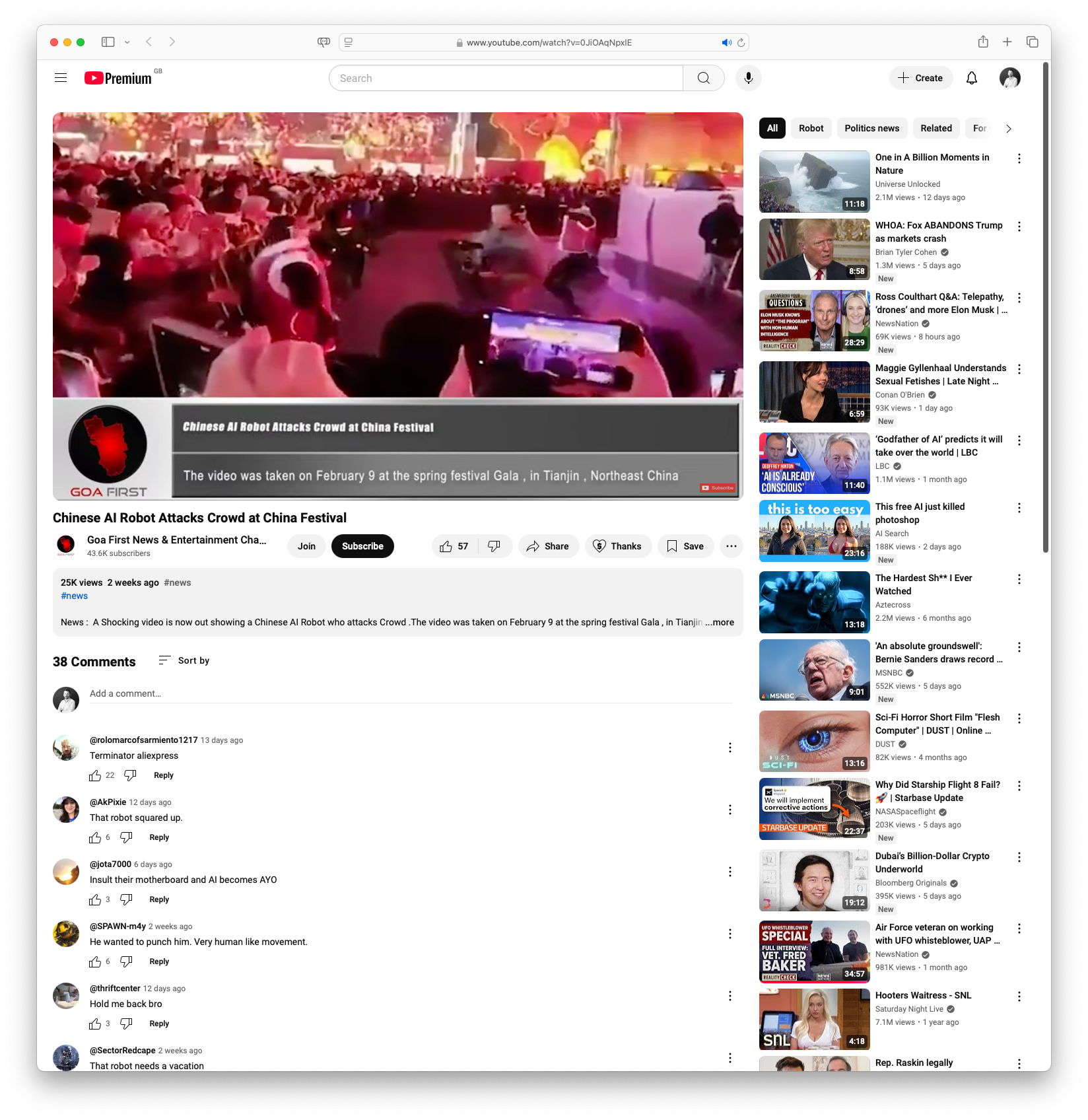
In a startling incident at a Chinese festival, a video has emerged showing an AI robot attacking the crowd during the Spring Festival Gala. The shocking footage was captured on February 9, and has since gone viral, raising questions about the safety and control measures of AI technologies used in public environments. This event has sparked widespread concern and discussions regarding the integration and regulation of AI in public spaces.
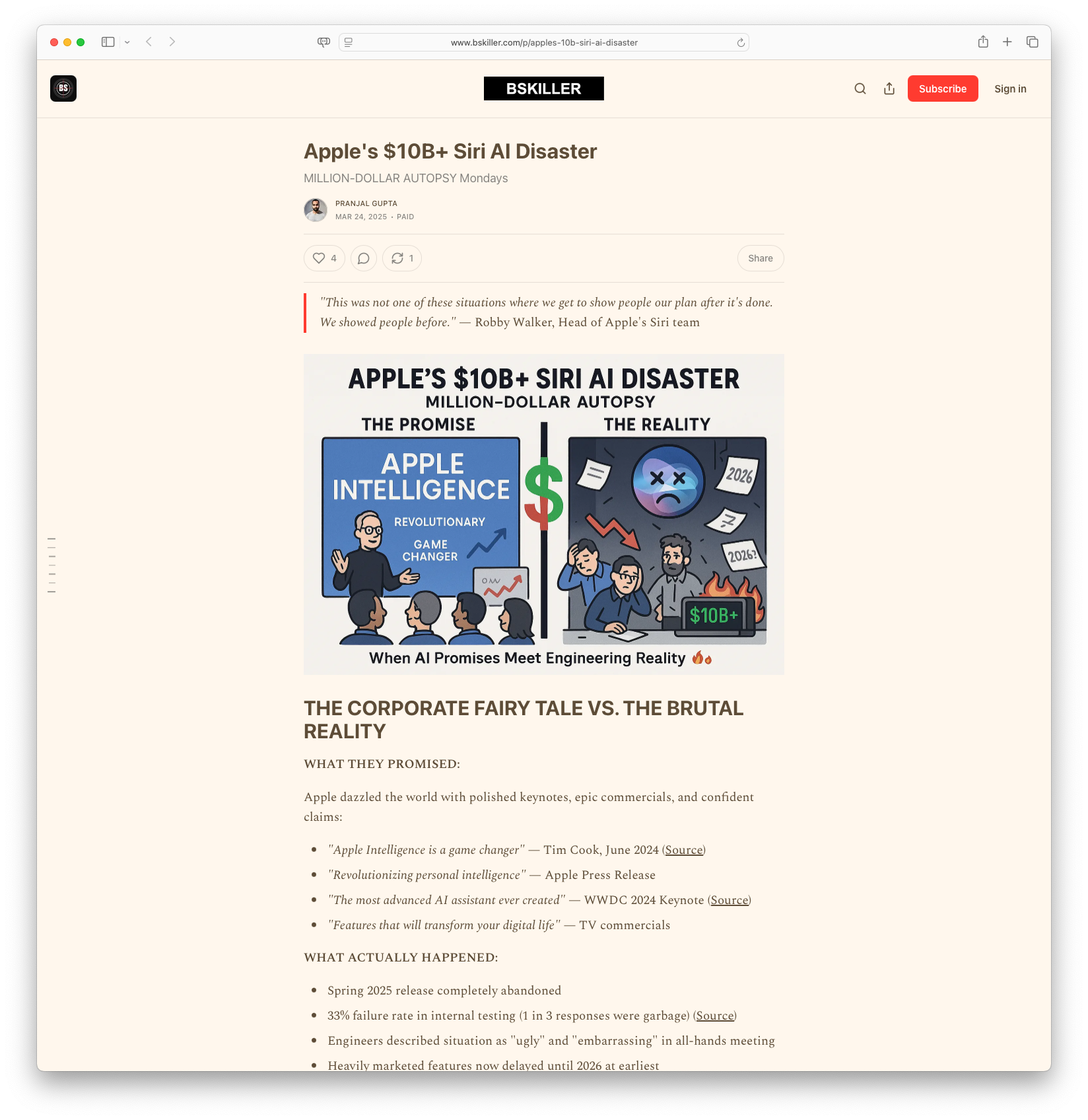
The article, titled 'Apple's $10B+ Siri AI Disaster,' provides an in-depth examination of Apple's considerable challenges with its Siri AI development. Promising revolutionary advancements, Apple faced internal failures, leading to a 33% response error rate in testing and delaying key features until 2026. The piece questions how even with substantial cash reserves and expert engineers, Apple faltered, casting doubt on AI reliability for other companies as well.
The article explores the dual nature of using AI tools for coding, with a focus on the Cursor application. Despite being able to drastically improve coding efficiency, the author describes how these AI tools can be problematic, producing 'garbage' output at times. The key to a successful experience, according to the author, is to maintain a balance between automation and human oversight, minimizing the input and incorporating customizations through simplified rules to curb common AI errors.
The article reflects on how reliance on generative AI tools, initially helpful for routine tasks like analytics integration, can lead to diminished problem-solving abilities and increased frustration when the tools fall short. The author compares this dependence to a form of addiction, questioning the long-term cognitive and creative consequences of overusing AI.
AI Blindspots discusses common pitfalls encountered when working with Large Language Models (LLMs) during AI coding. It outlines several strategies in the form of a 'sonnet family' approach to mitigate these issues. The site suggests potential solutions or rules like black-box testing, using a bulldozer method, and emphasizing reading documentation.
Regards,
M@
[ED: If you'd like to sign up for this content as an email, click here to join the mailing list.]
Originally published on quantumfaxmachine.com and cross-posted on Medium.
hello@matthewsinclair.com | matthewsinclair.com | bsky.app/@matthewsinclair.com | masto.ai/@matthewsinclair | medium.com/@matthewsinclair | xitter/@matthewsinclair
Was this useful?