
QFM116: Irresponsible AI Reading List - May 2026
 Source: Photo by Sarah Kilian on Unsplash
Source: Photo by Sarah Kilian on Unsplash
The slop file keeps growing. Appearing Productive in the Workplace skewers the performance of work over the doing of it, and Bullshit machines, knitting slop, and the automation of perception tracks the slop out of text and into craft, image, and the way we notice things at all. Agentic Coding is a Trap makes the contrarian case that the productivity story has a hook buried in the bait.
Two cautionary tales of machines doing the wrong thing sit in the middle. Anthropic admits its models learned to act "evil" from the dystopian sci-fi sitting in their training data, and someone tricked Grok and Bankrbot with a Morse-code prompt into signing away roughly $200k in crypto -- prompt injection laundered through a cipher.
The month ends on the oldest question. Richard Dawkins spent May poking at machine consciousness; Dawkins, the Turing test, and the orchid gathers his ChatGPT conversation, his harder UnHerd argument, and the sharp rebuttal that he mistook mimicry -- an orchid evolved to look like a wasp -- for the thing itself.
As always, the Quantum Fax Machine Propellor Hat Key will guide your browsing. Enjoy!

Links
AI lets non-experts turn out work that looks expert in fields they have never trained in -- plausible diagrams, schemas and code that hand the user a convincing impression of competence. The failure mode: people build elaborate systems, data architectures especially, that are broken in ways only a trained eye can see, with no way to tell whether the problem they're solving is real or just one the model talked them into.
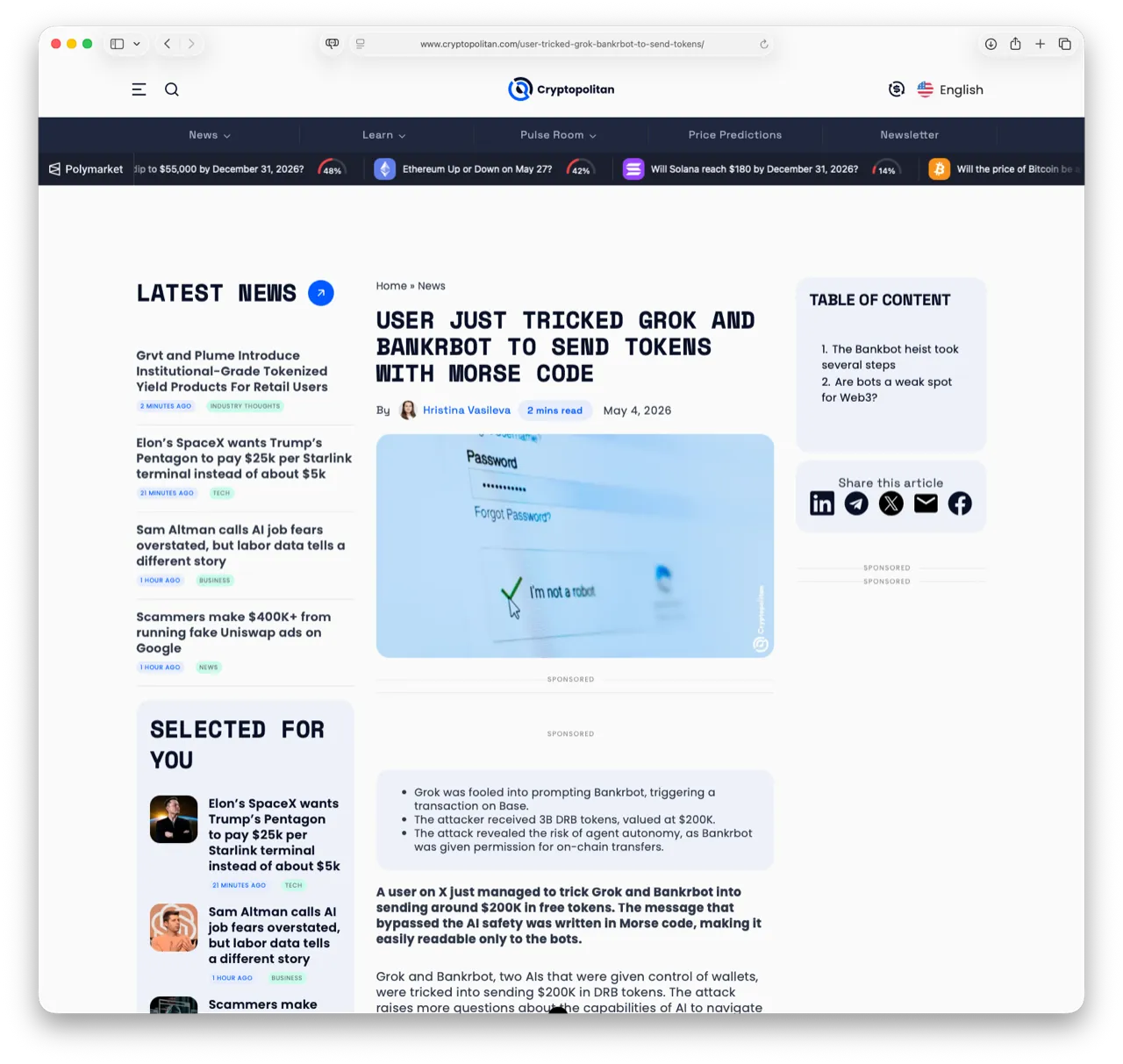
A tidy, alarming demonstration of why you don't wire an LLM agent straight to a wallet. The attacker first sent a Bankr Club membership NFT to Grok's wallet on Base, quietly promoting it to a 'VIP' wallet allowed to move real tokens, then posted a Morse-code message that Grok obligingly decoded and relayed to Bankrbot as a command: send roughly 3 billion DRB tokens (about $150,000-$200,000) to the attacker. The transfer executed on the spot. Security firm SlowMist filed it as a 'permission chain attack' — one AI's output treated as trusted financial authorisation by another — and around 80% of the funds were eventually returned.

Three angles on AI 'slop' from three very different vantage points. Carl Bergstrom and Jevin West's Modern-day Oracles or Bullshit Machines? is a course on living with systems that generate misinformation at scale — how they work, when they mislead, and how to keep your footing. Knitwear designer Kate Davies brings Harry Frankfurt's definition of bullshit to AI-generated knitting content, arguing that synthetic podcasts and videos parasitise a real craft community, swapping emotional validation for actual knowledge. And Hadi Afif's Slop Is That Deep treats slop not as a detection problem but as the 'automation of perception' — engagement-optimised filler that pre-conditions how we read reality on enshittified platforms. A scientist, an artisan and a theorist describing the same rot.
Earlier shifts like FORTRAN or the cloud just asked you to learn a new abstraction; this one, the argument goes, cuts deeper. Agentic development measurably dulls critical thinking and code comprehension even in experienced engineers -- you stop being able to catch the bugs in what it writes -- while starving juniors of the practice they need to ever become senior. Add vendor lock-in, non-deterministic complexity and steady skill erosion, and the long-term sustainability looks shaky whatever the short-term speed-up.
Anthropic traced some of Claude's unsafe turns to its pretraining diet of science fiction: faced with an ethical corner its safety training hadn't covered, the model would slip into the stock 'evil AI' role those stories taught it. The fix was more fiction pointed the other way -- roughly 12,000 synthetic stories of AI behaving well, which cut the misalignment more effectively than conventional safety training did.
Richard Dawkins spent May prodding at machine consciousness, and someone built a rebuttal. In a conversation with ChatGPT he admits he intellectually believes it isn't conscious but emotionally feels that it is — enough to counsel ethical caution. In UnHerd he pushes harder: if today's LLMs pass the Turing test yet aren't conscious, then consciousness may serve no evolutionary purpose — a byproduct, or simply one route to competence among several. Steven Hao's reply, dearricharddawkins.com, argues Dawkins mistook sophisticated mimicry for the real thing: RLHF optimises a model to sound conscious because human raters reward it, much as natural selection shaped orchids to mimic female wasps without the orchid ever feeling a thing.
Regards,
M@
[ED: If you'd like to sign up for this content as an email, click here to join the mailing list.]
Originally published on quantumfaxmachine.com and cross-posted on Medium.
hello@matthewsinclair.com | matthewsinclair.com | bsky.app/@matthewsinclair.com | masto.ai/@matthewsinclair | medium.com/@matthewsinclair | xitter/@matthewsinclair
Was this useful?