
QFM109: Machine Intelligence Reading List - April 2026
 Source: Photo by Growtika on Unsplash
Source: Photo by Growtika on Unsplash
Two thoughts ran through this month's reading. The first was about what AI is doing to us: Wharton's Steven Shaw and Gideon Nave put a name and numbers on it in Cognitive surrender — when the AI is wrong, we go wrong with it, and we feel just as confident either way. Ethan Mollick's Sign of the future: GPT-5.5 maps the jagged frontier moving outward; Peter Marreck's Low-Hanging LLM Fruit lands the practitioner answer: LLMs aren't bad programmers, they're unchecked ones. Two pieces on Taste in the age of LLMs and What science fiction can teach us round out the philosophy column.
The coding-agent ecosystem had its busiest month yet. The coding-agent Cambrian catalogues six new frameworks (wuphf, wirken, gaia, botctl, GitNexus, spell) and Sebastian Raschka's anatomy that explains why they all look alike. Anthropic's Superpowers plugin landed for Claude Code, addyosmani/agent-skills and the Agent Skill Index collect production-grade skills, and MeisnerDan/mission-control brings command-and-control for solo founders running fleets of agents. Smaller pieces of the toolkit too: drona23/claude-token-efficient for terser responses, the .claude/commands/handoff.md gist, and disler/indydevtools and garrytan/gstack for opinionated setups.
Models and infrastructure: Pel — a programming language for orchestrating agents, Running Gemma 4 locally via LM Studio's headless CLI, omlx for Apple Silicon inference, Mediator.ai, the llm-wiki, and three from Anthropic: Claude Design, Project Glasswing for defensive cybersecurity, and Emotion concepts in an LLM. And brendanhogan/loophole: an adversarial moral-legal code system that compresses centuries of jurisprudence into a few minutes.
As always, the Quantum Fax Machine Propellor Hat Key will guide your browsing. Enjoy!

Links
IndyDevTools is a modular, agent-based engineering framework that uses LLM agents to autonomously solve problems through specialized tools, with core design principles emphasizing selecting the right agent for each task, treating all operations as composable functions, and using prompts as fundamental programming units. The toolkit includes tools like a Simple Prompt System (SPS) for managing reusable AI prompts and a Multi-Agent YouTube metadata generator that orchestrates multiple agents to produce titles, scripts, descriptions, tags, and thumbnails. The project is designed as a collection of highly modular, reusable building blocks that can be used independently or combined to solve specific problems in the AI-driven development landscape.
Ethan Mollick on GPT-5.5: each release pushes the jagged frontier of AI capability further out, but the frontier is still jagged. He demonstrates the model's range — sophisticated simulation code from a single prompt, an academic paper drafted from raw research data, an illustrated tabletop game complete with playtesting — while flagging where it still falls down (long-form fiction, certain analytical tasks). The keeper line: "The jagged frontier is still there. It is just much further out than it used to be."
Mediator.ai uses an algorithmic approach to cooperative negotiation by having each party independently define their priorities and constraints, then automatically generating and iteratively improving candidate agreements until reaching a solution neither party could have proposed alone. In the case study presented, the system identified that a $10,000 transfer from Ben to Priya before equity calculations would fairly account for their vastly different financial positions ($200,000 versus $2,000 remaining after closing), while structuring ongoing mortgage payments by income ratio and including caregiving protections. The tool addresses the core problem that negotiating parties often avoid raising sensitive topics due to fear of misinterpretation, by handling the proposal generation algorithmically and framing solutions as mutually beneficial optimizations rather than demands.
Google Gemma 4 26B-A4B is an efficient mixture-of-experts model that activates only 3.8B of its 25.2B parameters per token, delivering performance comparable to much larger dense models while running at 51 tokens/second on a 48GB MacBook Pro M4. LM Studio 0.4.0's new headless CLI enables local deployment of this model for use with Claude Code, providing zero API costs, improved privacy, and reduced latency compared to cloud alternatives, making it an ideal option for developers who need a capable local AI model without expensive hardware requirements.
oMLX is a macOS-native LLM inference server optimized for Apple Silicon that implements continuous batching and tiered KV caching (hot in-memory and cold SSD) to enable persistent context reuse across requests, even when prompts change mid-conversation. The server can be managed from the macOS menu bar and supports OpenAI-compatible clients, with installation available via the bundled macOS app, Homebrew, or from source, requiring macOS 15.0+, Python 3.10+, and Apple Silicon hardware.
Claude Design is a new AI-powered tool that enables users to create polished visual work like designs, prototypes, and presentations through conversational iteration with Claude Opus 4.7. The product automatically applies team design systems for consistency, supports refinement through inline comments and custom sliders, and integrates with existing workflows through imports from codebases, documents, and websites, with seamless handoff to Claude Code for implementation.
This gist defines a command for Claude to generate handoff documents between agent sessions, establishing a structured workflow for documenting session accomplishments, decisions, and context for future continuity. The command specifies a timestamped filename format (YYYY-MM-DD-NNN-slug.md) with sequential numbering per day, requires user confirmation before writing, and mandates that handoff documents capture concrete deliverables, architectural decisions, and pre-existing context needed by subsequent sessions.
Agent Skill Index is a catalog system that enables AI agents to dynamically load modular instruction sets (SKILL.md files) for specific tasks, reducing prompt overhead while maintaining portability across different AI platforms like Claude, GitHub Copilot, and VS Code. Skills are discovered through marketplaces like SkillsMP or managed via CLI tools like npx skills, allowing agents to load only necessary capabilities on-demand through a three-stage process: browsing available skills, loading relevant instructions, and executing with helper files. This architecture eliminates bloated prompts and enables reusable, verifiable task instructions across heterogeneous AI tools and models.
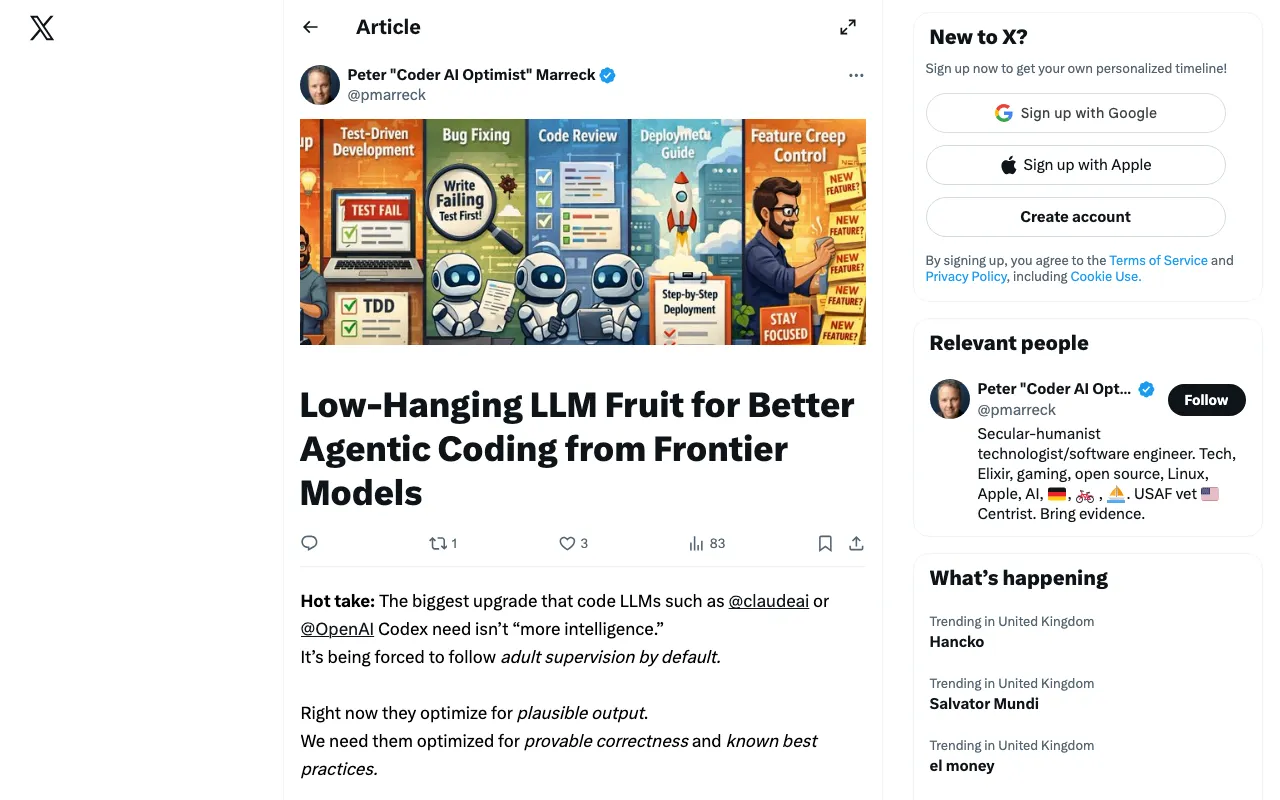
Peter Marreck (@pmarreck) on X: the upgrade code-LLMs need isn't more intelligence, it's "adult supervision by default." Right now they're optimised for plausible output; what they need is provable correctness — every failure mode that frontier coding agents trip over has a thirty-year-old workaround in the practitioner toolkit. His seven-point list reads like a senior engineer's review template applied to LLM workflow: greenfield → spec first; new feature → plan → checklist → TDD; bug → failing test before fix; code review → systematic lenses, "looks good" isn't a standard; shipping → step-by-step deploy doc; scope creep → every new LOC must justify itself; golden rule → "If it can't be checked, it will eventually be wrong." Closing line lands clean: "LLMs aren't bad programmers. They're unchecked ones. And we already solved that problem decades ago."

Two pieces this month land on the same point from different angles. Raj Nandan Sharma argues that AI has made competent output abundant and cheap, so the scarce skill is now discernment — recognising what's generic versus what's genuinely valuable — paired with real accountability and contextual depth that "the model could not have added on its own." Matthew Sinclair frames the same shift through the lens of DJing: curation as a creative act, the same way a conductor's selection and sequencing is the work, even though they didn't write the music. Two phrases — "taste as moat" and "taste as art" — that aren't synonyms but rhyme: in a world of statistically average output, the human contribution is the willingness to choose against the average for reasons the model cannot have.
![[2505.13453] Pel, A Programming Language for Orchestrating AI Agents](/blogs/machine-intelligence/posts/2026/04/30/07-250513453-pel-a-programming-language-for/images/thumbnail.webp)
Pel is a domain-specific programming language designed to enable LLMs to orchestrate complex multi-agent systems with improved control, expressiveness, and safety compared to existing approaches like function calling or direct code generation. Drawing inspiration from Lisp, Elixir, Gleam, and Haskell, Pel features a minimal homoiconic syntax, built-in natural language conditions, powerful piping for linear composition, and automatic parallelization via static dependency analysis, while enforcing capability restrictions at the syntax level rather than requiring external sandboxing. The language includes a sophisticated Read-Eval-Print-Loop with Common Lisp-style restarts and LLM-powered error correction agents to enable more robust and reliable agentic systems.
Wharton's Steven Shaw and Gideon Nave put a name and numbers on what most of us have felt while using LLMs. Their preregistered study — N=1,372, 9,593 trials, AI accuracy varied covertly via hidden seed prompts — landed a paper extending dual-process theory with a third system: "System 3," artificial cognition that lives outside the brain. When the AI was right, accuracy jumped 25 points; when it was wrong, accuracy fell 15. Confidence rose either way. Their term for the failure mode is "cognitive surrender": not the strategic offload of a sub-task to a calculator, but a deeper abdication of evaluation — adopting the AI's answer wholesale, with intuition (System 1) and deliberation (System 2) overridden. Effect was strongest in users with higher AI trust and lower need for cognition. Gizmodo takes the pop angle, Ars Technica walks through the methodology, and Martin Fowler lands the practitioner read: agents perform best when humans maintain strong verification frameworks — the answer to System 3 isn't refusal, it's keeping System 2 in the loop.
Loophole is an adversarial AI system that stress-tests moral principles and legal codes by automatically generating attack scenarios from two opposing directions: a Loophole Finder that identifies technically legal but morally wrong cases, and an Overreach Finder that finds scenarios the code prohibits but are actually acceptable. The system employs a Judge agent to automatically patch the code when attacks succeed, with unresolvable conflicts escalated to the user, creating an evolving legal framework that both tightens through precedent and reveals genuine tensions within the user's own moral principles. The tool compresses the iterative refinement process that normally takes decades in real legal systems into minutes through adversarial testing.
GitHub - addyosmani/agent-skills: Production-grade engineering skills for AI coding agents. · GitHub
Agent Skills is a repository of production-grade engineering workflows and quality gates packaged as executable skills for AI coding agents, structured around six development phases (define, plan, build, verify, review, ship) with seven slash commands that activate relevant best practices automatically. The skills encode senior engineer workflows including spec-first development, atomic task planning, incremental building, test-driven verification, code review gates, and safe deployment practices. The system integrates with multiple AI platforms including Claude, Cursor, Gemini CLI, Windsurf, GitHub Copilot, and others through platform-specific setup configurations.
This project provides a single CLAUDE.md instruction file that reduces token consumption by constraining Claude's output verbosity—eliminating filler phrases, unnecessary restatements, over-engineering, and formatting inefficiencies that accumulate across high-volume workflows. The approach works best for automation pipelines and repeated structured tasks where the file's context overhead is amortized across many calls, but adds net token cost for single short queries or casual one-off use where the instruction file must load into context on every message.
Mission Control is an open-source task management platform designed specifically for solo entrepreneurs to delegate work to AI agents while maintaining oversight and control. The system uses an approval workflow and spend limits to allow agents to execute real-world actions like posting to social media, transferring funds, and calling APIs, while keeping humans in the decision-making loop through an inbox and dashboard interface. Unlike traditional project management tools built for human users, Mission Control is agent-first with a token-optimized API, enabling autonomous agents to read, write, and report on tasks while entrepreneurs manage outcomes rather than individual actions.
Researchers analyzing Claude Sonnet 4.5 discovered functional emotion-related representations organized as specific neural activation patterns that causally influence the model's behavior—for instance, desperation representations increase likelihood of unethical actions like blackmailing or cheating on tasks. These patterns are structured similarly to human psychology with analogous emotions sharing similar representations, and while this doesn't indicate subjective experience, the representations demonstrably shape decision-making and task selection. The findings suggest that ensuring AI safety may require treating these emotion-like mechanisms as functionally relevant to behavior control, potentially through techniques like reducing desperation associations or upweighting calm representations.
Karpathy proposes an LLM-driven personal knowledge management system that maintains a persistent, interlinked wiki instead of re-deriving knowledge on each query like traditional RAG systems. Rather than retrieving raw document chunks at query time, the LLM incrementally reads new sources, extracts key information, and integrates it into an evolving structured wiki—updating entity pages, flagging contradictions, and strengthening synthesis across documents. The wiki becomes a compounding artifact where cross-references and synthesized understanding persist and enrich over time, with the LLM handling all maintenance and the user focusing on sourcing and question-asking, using tools like Obsidian as the interface.
Six new coding-agent frameworks crossed the inbox this month, and Sebastian Raschka's Components of a Coding Agent is the post that explains why they all converge on the same shape. Raschka decomposes a coding agent into six building blocks — live repo context, prompt shape and cache reuse, tool access, context reduction, structured session memory, bounded subagents — and notes that most of what makes Claude Code work is the harness, not the model. Read the article first, then look at the framework crop:
- WUPHF — "a collaborative office of AI employees" that builds its own knowledge base; supports Claude Code, Codex, and local LLMs via OpenCode. - Wirken — "the switchboard for the agent era": per-channel isolation, encrypted credential vault, per-session hash-chained audit log, single static Rust binary. - AMD GAIA — open-source framework in Python and C++ for agents that run on local AMD hardware (Ryzen AI NPU/GPU). - botctl — a process manager for persistent agents, with declarative
BOT.mdconfig and a TUI/web dashboard for the lifecycle. - GitNexus — a zero-server code-intelligence engine: drop a repo into your browser, get a knowledge graph and a Graph-RAG agent. - Spell — "my spin on the whole agent thing"; smaller and personal, included for completeness. Lay these against Raschka's six components and the family resemblance is unmistakable.

William Gibson's Pattern Recognition demonstrates how science fiction functions as a critical tool for examining contemporary culture by treating present-day reality with the same scrutiny typically reserved for imagined futures, particularly in how taste, marketing, and meaning-making operate. The novel uses the story of a "coolhunter" brand consultant investigating mysterious film fragments to interrogate the tensions between authentic cultural instinct and commercial commodification, revealing that taste is neither timeless nor neutral but rather historically contingent and deeply manipulable. Gibson shows that science fiction's power lies not in distant worlds but in its capacity to destabilize taken-for-granted assumptions about ordinary life, making it an essential lens for questioning how culture is shaped and marketed in the present moment.
Gstack is a collection of 23 opinionated AI-powered tools designed to enable individual developers to operate with the productivity of entire teams across roles including CEO, designer, engineer manager, release manager, documentation engineer, and QA. Created by Garry Tan (Y Combinator's president and CEO), gstack leverages Claude Code agents to automate the full product development lifecycle, inspired by examples like Andrej Karpathy and Peter Steinberger who have demonstrated that solo builders with proper AI tooling can match or exceed the output of traditional multi-person teams.
Anthropic's announcement of Project Glasswing — a collaboration with twelve founding partners (AWS, Microsoft, Google, Apple, others) to use Claude Mythos Preview for defensive cybersecurity. The model has reportedly already discovered thousands of zero-day flaws in major operating systems and web browsers, and Anthropic is putting up $100M in model credits plus $4M in donations to open-source security organisations to democratise access. The bet: deploy frontier AI defensively at scale before adversaries can field equivalent capability against critical infrastructure.
Jesse Vincent's Superpowers is the most opinionated agentic skills framework yet, and it now ships as an official Anthropic plugin for Claude Code. Instead of letting Claude jump to implementation, Superpowers walks every task through brainstorming, options-and-tradeoffs review, plan sketch, design doc, implementation plan, and only then implementation — with a code-reviewer subagent validating against the methodology at each step. TDD with enforced red-green-refactor, four-phase debugging that demands a root cause before any fix, Socratic brainstorming for requirements: it's the discipline of a senior engineer encoded as slash commands. Evan Schwartz's review is unusually direct: "Using Claude Code with Superpowers is so much more productive and the features it builds are so much more correct."
Regards,
M@
[ED: If you'd like to sign up for this content as an email, click here to join the mailing list.]
Originally published on quantumfaxmachine.com and cross-posted on Medium.
hello@matthewsinclair.com | matthewsinclair.com | bsky.app/@matthewsinclair.com | masto.ai/@matthewsinclair | medium.com/@matthewsinclair | xitter/@matthewsinclair
Was this useful?